Python 3.x可能是史上最详解的【
发布时间:2019-08-26 07:52:26编辑:auto阅读(2337)
- 每个函数function 有自己的命名空间,称local namespace,记录函数的变量。
- 每个模块module 有自己的命名空间,称global namespace,记录模块的变量,包括functions、classes、导入的modules、module级别的变量和常量。
- build-in命名空间,它包含build-in function和exceptions,可被任意模块访问。
- local namespace 即当前函数或类方法。若找到,则停止搜索;
- global namespace 即当前模块。若找到,则停止搜索;
- build-in namespace Python会假设变量x是build-in的函数函数或变量。若变量x不是build-in的内置函数或变量,Python将报错NameError。
- 对于闭包,若在local namespace找不到该变量,则下一个查找目标是父函数的local namespace。
- from module_A import X:会将该模块的函数/变量导入到当前模块的命名空间中,无须用module_A.X访问了。
- import module_A:modules_A本身被导入,但保存它原有的命名空间,故得用module_A.X方式访问其函数或变量。
- name 直接运行本模块, name 值为 main ;import module, name 值为模块名字。
- file 当前 module的绝对路径
- dict
- doc
- package
- path
如需转载请注明出处。
win10+Python 3.6.3
一旦使用多层文件架构就很容易遇上import的坑!哈哈。
一、理解一些基本概念
1、模块、包
模块 module:一般情况下,是一个以.py为后缀的文件。其他可作为module的文件类型还有”.pyo”、”.pyc”、”.pyd”、”.so”、”.dll”,但Python初学者几乎用不到。
module 可看作一个工具类,可共用或者隐藏代码细节,将相关代码放置在一个module以便让代码更好用、易懂,让coder重点放在高层逻辑上。
module能定义函数、类、变量,也能包含可执行的代码。module来源有3种:
①Python内置的模块(标准库);
②第三方模块;
③自定义模块。
包 package: 为避免模块名冲突,Python引入了按目录组织模块的方法,称之为 包(package)。包 是含有Python模块的文件夹。
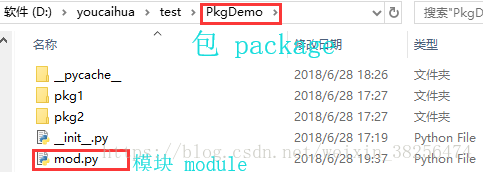
当一个文件夹下有 init .py时,意为该文件夹是一个包(package),其下的多个模块(module)构成一个整体,而这些模块(module)都可通过同一个包(package)导入其他代码中。
其中 init .py文件 用于组织包(package),方便管理各个模块之间的引用、控制着包的导入行为。
该文件可以什么内容都不写,即为空文件(为空时,仅仅用import [该包]形式 是什么也做不了的),存在即可,相当于一个标记。
但若想使用from pacakge_1 import *这种形式的写法,需在 init .py中加上: all = [‘file_a’, ‘file_b’] #package_1下有file_a.py和file_b.py,在导入时 init .py文件将被执行。
但不建议在 init .py中写模块,以保证该文件简单。不过可在 init .py导入我们需要的模块,以便避免一个个导入、方便使用。
其中, all 是一个重要的变量,用来指定此包(package)被import *时,哪些模块(module)会被import进【当前作用域中】。不在 all 列表中的模块不会被其他程序引用。可以重写 all ,如 all = [‘当前所属包模块1名字’, ‘模块1名字’],如果写了这个,则会按列表中的模块名进行导入。
在模糊导入时,形如from package import *,*是由__all__定义的。
精确导入,形如 from package import *、import package.class。
path 也是一个常用变量,是个列表,默认情况下只有一个元素,即当前包(package)的路径。修改 path 可改变包(package)内的搜索路径。
当我们在导入一个包(package)时(会先加载 init .py定义的引入模块,然后再运行其他代码),实际上是导入的它的 init .py文件(导入时,该文件自动运行,助我们一下导入该包中的多个模块)。我们可以在 init .py中再导入其他的包(package)或模块 或自定义类。
2、sys.modules、命名空间、模块内置属性
2.1 sys.modules
官方解释:链接
sys.modules 是一个 将模块名称(module_name)映射到已加载的模块(modules) 的字典。可用来强制重新加载modules。Python一启动,它将被加载在内存中。
当我们导入新modules,sys.modules将自动记录下该module;当第二次再导入该module时,Python将直接到字典中查找,加快运行速度。
它是个字典,故拥有字典的一切方法,如sys.modules.keys()、sys.modules.values()、sys.modules[‘os’]。但请不要轻易替换字典、或从字典中删除某元素,将可能导致Python运行失败。
import sys
print(sys.modules)#打印,查看该字典具体内容。2.2 命名空间
如同一个dict,key 是变量名字,value 是变量的值。
某段Python代码访问 变量x 时,Python会所有的命名空间中查找该变量,顺序是:
例:namespace_test.py代码
def func(a=1):
b = 2
print(locals())#打印当前函数(方法)的局部命名空间
'''
locs = locals()#只读,不可写。将报错!
locs['c'] = 3
print(c)
'''
return a+b
func()
glos = globals()
glos['d'] = 4
print(d)
print(globals())#打印当前模块namespace_test.py的全局命名空间内置函数locals()、globals()返回一个字典。区别:前者只读、后者可写。
命名空间 在from module_name import 、import module_name中的体现:from关键词是导入模块或包中的某个部分。
2.3 模块内置属性
3、绝对导入、相对导入

3.1 绝对导入:所有的模块import都从“根节点”开始。根节点的位置由sys.path中的路径决定,项目的根目录一般自动在sys.path中。如果希望程序能处处执行,需手动修改sys.path。
例1:c.py中导入B包/B1子包/b1.py模块
import sys,os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))#存放c.py所在的绝对路径
sys.path.append(BASE_DIR)
from B.B1 import b1#导入B包中子包B1中的模块b1例2:b1.py中导入b2.py模块
from B.B1 import b2#从B包中的子包B1中导入模块b23.2 相对导入:只关心相对自己当前目录的模块位置就好。不能在包(package)的内部直接执行(会报错)。不管根节点在哪儿,包内的模块相对位置都是正确的。
b1.py代码
#from . import b2 #这种导入方式会报错。
import b2#正确
b2.print_b2()b2.py代码
def print_b2():
print('b2')运行b1.py,打印:b2。
在使用相对导入时,可能遇到ValueError: Attempted relative import beyond toplevel package
解决方案:参考这篇文章,链接。
3.3 单独导入包(package):单独import某个包名称时,不会导入该包中所包含的所有子模块。
c.py导入同级目录B包的子包B1包的b2模块,执行b2模块的print_b2()方法:
c.py代码
import B
B.B1.b2.print_b2()运行c.py,会报错。
解决办法:
B/ init .py代码
from . import B1#其中的.表示当前目录B/B1/ init .py代码
from . import b2此时,执行c.py,成功打印:b2。
3.4 额外
①一个.py文件调用另一个.py文件中的类。
如 a.py(class A)、b.py(class B),a.py调用b.py中类B用:from b import B
②一个.py文件中的类 继承另一个.py文件中的类。如 a.py(class A)、b.py(class B),a.py中类A继承b.py类B。
from b import B
class A(B):
pass二、Python运行机制:理解Python在执行import语句(导入内置(Python自个的)或第三方模块(已在sys.path中))时,进行了啥操作?
step1:创建一个新的、空的module对象(它可能包含多个module);
step2:将该module对象 插入sys.modules中;
step3:装载module的代码(如果需要,需先编译);
step4:执行新的module中对应的代码。
在执行step3时,首先需找到module程序所在的位置,如导入的module名字为mod_1,则解释器得找到mod_1.py文件,搜索顺序是:
当前路径(或当前目录指定sys.path)—–>PYTHONPATH—–>Python安装设置相关的默认路径。
对于不在sys.path中,一定要避免用import导入 自定义包(package)的子模块(module),而要用from…import… 的绝对导入 或相对导入,且包(package)的相对导入只能用from形式。
1、“标准”import,顶部导入
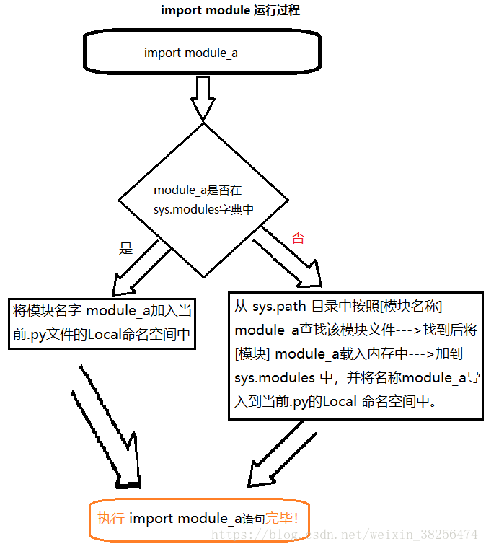
有上述基础知识,再理解这个思维导图,就很容易了。在运用模块的变量或函数时,就能得心应手了。
2、嵌套import
2.1 顺序导入-import
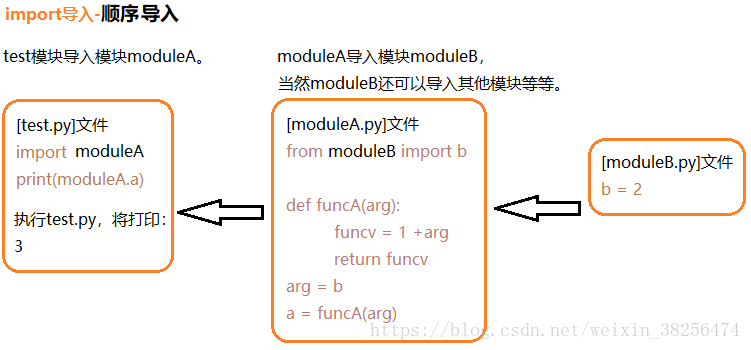
PS:各个模块的Local命名空间的独立的。即:
test模块 import moduleA后,只能访问moduleA模块,不能访问moduleB模块。虽然moduleB已加载到内存中,如需访问,还得明确地在test模块 import moduleB。实际上打印locals(),字典中只有moduleA,没有moduleB。
2.2 循环导入/嵌套导入-import
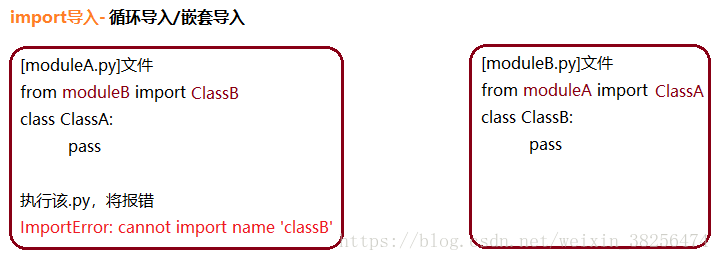
形如from moduleB import ClassB语句,根据Python内部import机制,执行细分步骤:
1. 在sys.modules中查找 符号“moduleB”;
2. 如果符号“moduleB”存在,则获得符号“moduleB”对应的module对象;
从的 dict__中获得 符号“ClassB”对应的对象。如果“ClassB”不存在,则抛出异常“ImportError: cannot import name ‘classB’”
3. 如果符号“moduleB”不存在,则创建一个新的 module对象。不过此时该新module对象的 dict 为空。然后执行moduleB.py文件中的语句,填充的 dict 。
总结:from moduleB import ClassB有两个过程,先from module,后import ClassB。
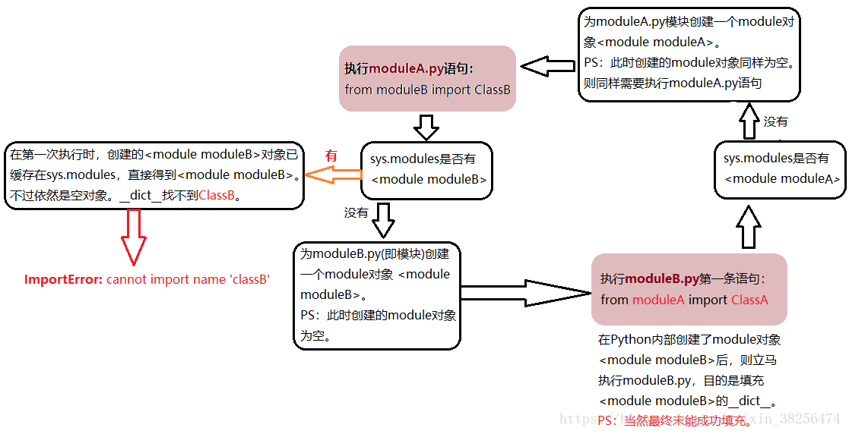
当然将moduleA.py语句 from moduleB import ClassB改为:import moduleB,将在第二次执行moduleB.py语句from moduleA import ClassA时报错:ImportError: cannot import name ‘classA’
解决这种circular import循环导入的方法:
例比:安装无线网卡时,需上网下载网卡驱动;
安装压缩软件时,从网上下载的压缩软件安装程序是被压缩的文件。
方法1—–>延迟导入(lazy import):把import语句写在方法/函数里,将它的作用域限制在局部。(此法可能导致性能问题)
方法2—–>将from x import y改成import x.y形式
方法3—–>组织代码(重构代码):更改代码布局,可合并或分离竞争资源。
合并—–>都写到一个.py文件里;
分离–>把需要import的资源提取到一个第三方.py文件中。
总之,将循环变成单向。
3、包(package)import
在一个文件下同时有 init .py文件、和其他模块文件时,该文件夹即看作一个包(package)。包的导入 和模块导入基本一致,只是导入包时,会执行这个 init .py,而不是模块中的语句。
而且,如果只是单纯地导入包【形如:import xxx】,而包的 init .py中有没有明确地的其他初始化操作,则:此包下的模块 是不会被自动导入的。当然该包是会成功导入的,并将包名称放入当前.py的Local命名空间中。
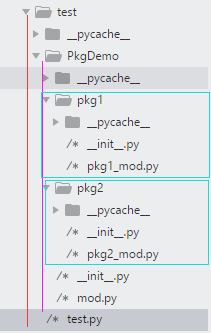
[D:youcaihua\test\PkgDemo\mod.py]文件
[D:youcaihua\test\PkgDemo\pkg1\pkg1_mod.py]文件
[D:youcaihua\test\PkgDemo\pkg2\pkg2_mod.py]文件,三个文件同样的代码:
def getName():
print(__name__)
if __name__ == '__main__':
getName()[D:youcaihua\test\test.py]文件
import PkgDemo.mod#1
print(locals(),'\n')
import PkgDemo.pkg1#2
print(locals(),'\n')
import PkgDemo.pkg1.pkg1_mod as m1#3
print(locals(),'\n')
import PkgDemo.pkg2.pkg2_mod#4
PkgDemo.mod.getName()#5
print('调用mod.py----', locals(), '\n')
m1.getName()#6
PkgDemo.pkg2.pkg2_mod.getName()#7执行 #1 后,将PkgDemo、PkgDemo.mod加入sys.modules中,此时可调用PkgDemo.mod的任何类、或函数。当不能调用包PkgDemo.pkg1或pkg2下任何模块。但当前test.py文件Local命名空间中只有 PkgDemo。
执行 #2 后,只是将PkgDemo.pkg1载入内存,sys.modules会有PkgDemo、PkgDemo.mod、PkgDemo.pkg1 三个模块。但PkgDemo.pkg1下的任何模块 都没有自动载入内存,所以在此时:PkgDemo.pkg1.pkg1_mod.getName()将会出错。当前test.py的Local命名空间依然只有PkgDemo。
执行 #3 后,会将pkg1_mod载入内存,sys.modules会有PkgDemo、PkgDemo.mod、PkgDemo.pkg1、PkgDemo.pkg1.pkg1_mod四个模块,此时可执行PkgDemo.pkg1.pkg1_mod.getName()。由于使用了as,当前Local命名空间将另外添加m1(作为PkgDemo.pkg1.pkg1_mod的别名)、当然还有PkgDemo。
执行 #4 后,会将PkgDemo.pkg2、PkgDemo.pkg2.pkg2_mod载入内存,sys.modules中会有PkgDemo、PkgDemo.mod、PkgDemo.pkg1、PkgDemo.pkg1.pkg1_mod、PkgDemo.pkg2、PkgDemo.pkg2.pkg2_mod六个模块,当然:当前Local命名空间还是只有PkgDemo、m1。
#5、#6、#7当然都可正确执行。
三、How to avoid Python circle import error?如何避免Python的循环导入问题?
代码布局、(架构)设计问题,解决之道是:将循环变成单向。采用分层、用时导入、相对导入(层次建议不要超过两个)
注意:在命令行执行Python xx.py、与IDE中执行,结果可能不同。
如需转载请注明出处。
参考:
官方规范
上一篇: Python 3.5安装教程
下一篇: Python编程学习3:Python 对
- openvpn linux客户端使用
52582
- H3C基本命令大全
52510
- openvpn windows客户端使用
42593
- H3C IRF原理及 配置
39503
- Python exit()函数
33919
- openvpn mac客户端使用
30885
- python全系列官方中文文档
29665
- python 获取网卡实时流量
24572
- 1.常用turtle功能函数
24416
- python 获取Linux和Windows硬件信息
22788
- LangGraph Studio可视化
97°
- LangSmith开发-应用入门
108°
- LangGraph开发-多轮对话问答机器人
184°
- LangGraph开发-条件分支/循环图实战
179°
- LangGraph开发-生态介绍,入门demo实战
209°
- LangChain-接入12306-HTTP MCP智能体
368°
- LangChain接入自定义爬虫-MCP工具
359°
- LangChain接入Filesystem-MCP工具
365°
- LangChain搭建MCP服务端和客户端流程
440°
- LangGraph与MCP技术概述
363°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
