Python 3.x基于Xml数据的Ht
发布时间:2019-08-26 07:21:34编辑:auto阅读(2300)
- 基于urllib.request的Http访问
- 多线程
- 类与方法的定义
- 全局变量的定义与使用
- 文件的读取与写入
- ……
1. 前言
由于公司的一个项目是基于B/S架构与WEB服务通信,使用XML数据作为通信数据,在添加新功能时,WEB端与客户端分别由不同的部门负责,所以在WEB端功能实现过程中,需要自己发起请求测试,于是便选择了使用Python编写此脚本。另外由于此脚本最开始希望能在以后发展成具有压力测试的功能,所以除了基本的访问之外,添加了多线程请求。
整个脚本主要涉及到的关于Python的知识点包括:
2. 源码与结果
整个程序包括Python源码和配置文件,由于源码中有相应的注释,所以就直接贴源码吧,如下:
# TradeWeb测试脚本
import threading, time, http.client, urllib.request, os
#import matplotlib.pyplot as plt
URL = 'http://127.0.0.1:8888/XXXXXXXXX/httpXmlServlet' # 在配置文件中读取,此处将无效
TOTAL = 0; # 总数
SUCC = 0; # 响应成功数量
FAIL = 0; # 响应失败数量
EXCEPT = 0 # 响应异常数
MAXTIME = 0 # 最大响应时间
MINTIME = 100 # 最小响应时间,初始值为100秒
COUNT_TIME = 0 # 总时间
THREAD_COUNT = 0 # 记录线程数量
CODE_MAP = {200:0, 301:0, 302:0, 304:0} # 状态码信息(部分)
RESULT_FILE = 'tradeWebResult.xml' # 输出结果文件
REQUEST_DATA_FILE = 'requestData.config' # 数据文件
DATA = '''请在tradeWebRequestData.config文件中配置'''
TIME_LIST = [] # 记录访问时间
#创建一个threading.Thread的派生类
class RequestThread(threading.Thread):
#构造函数
def __init__(self, thread_name):
threading.Thread.__init__(self)
self.test_count = 0;
#线程运行的入口函数
def run(self):
global THREAD_COUNT
THREAD_COUNT += 1
#print("Start the count of thread:%d" %(THREAD_COUNT))
self.testPerformace()
#测试性能方法
def testPerformace(self):
global TOTAL
global SUCC
global FAIL
global EXCEPT
global DATA
global COUNT_TIME
global CODE_MAP
global URL
try:
st = time.time() #记录开始时间
start_time
cookies = urllib.request.HTTPCookieProcessor()
opener = urllib.request.build_opener(cookies)
resp = urllib.request.Request(url=URL,
headers={'Content-Type':'text/xml', 'Connection':'Keep-Alive'},
data=DATA.encode('gbk'))
respResult = opener.open(resp)
# 记录状态码 START
code = respResult.getcode()
if code == 200:
SUCC += 1
else:
FAIL += 1
if code in CODE_MAP.keys():
CODE_MAP[code] += 1
else:
CODE_MAP[code] = 1
# print(request.status)
# 记录状态码 END
html = respResult.read().decode('gbk')
print(html)
time_span = time.time() - st # 计算访问时间
# 记录访问时间
TIME_LIST.append(round(time_span * 1000))
# print('%-13s: %f ' %(self.name, time_span))
self.maxtime(time_span)
self.mintime(time_span)
self.writeToFile(html)
# info = respResult.info() # 响应头信息
# url = respResult.geturl() # URL地址
# print(info);
# print(url)
COUNT_TIME += time_span
TOTAL += 1
except Exception as e:
print(e)
TOTAL += 1
EXCEPT += 1
# 设置最大时间,如果传入的时间大于当前最大时间
def maxtime(self, ts):
global MAXTIME
#print("time:%f" %(ts))
if ts > MAXTIME:
MAXTIME = ts
# 设置最小时间,如果传入的时间小于当前最小时间
def mintime(self, ts):
global MINTIME
#print("time:%f" %(ts))
if ts < MINTIME and ts > 0.000000000000000001:
MINTIME = ts
# 写入文件
def writeToFile(self, html):
f = open(RESULT_FILE, 'w')
f.write(html)
f.write('\r\n')
f.close();
# 读取XML数据信息
def loadData():
global URL
global DATA
f = open(REQUEST_DATA_FILE, 'r')
URL = "".join(f.readline())
DATA = "".join(f.readlines())
# print(DATA)
f.close()
if __name__ == "__main__":
# print("============测试开始============")
print("")
# 开始时间
start_time = time.time()
# 并发的线程数
thread_count = 1
loadData() # 加载请求数据
i = 0
while i < thread_count:
t = RequestThread("Thread" + str(i))
t.start()
i += 1
t = 0
while TOTAL < thread_count and t < 60:
# print("total:%d, succ:%d, fail:%d, except:%d\n" %(TOTAL,SUCC,FAIL,EXCEPT))
print("正在请求 ",URL)
t += 1
time.sleep(1)
# 打印信息
print()
print("请求", URL, "的统计信息:")
print(" 总请求数 = %d,成功 = %d,失败 = %d,异常 = %d" %(TOTAL, SUCC, FAIL, EXCEPT))
print()
print("往返程的估计时间(以毫秒为单位):")
print(" 合计 =", int(COUNT_TIME * 1000), "ms", end = '')
print(" 最大 =", round(MAXTIME * 1000), "ms", end = '')
print(" 最小 =", round(MINTIME * 1000), "ms", end = '')
print(" 平均 =", round((COUNT_TIME / thread_count) * 1000), "ms")
print()
print("响应的状态码与次数信息(状态码:次数):")
print(" ", CODE_MAP)
print()
print("输出页面请查看", RESULT_FILE, "文件(建议使用浏览器或XML专业工具打开)")
print()
# os.system("pause")
print(TIME_LIST)
input()配置文件主要在于易于更改访问路径等,其中SESSION_ID是在Fiddler中抓包获取,配置文件源文件如下(为不泄露公司隐私,数据并非原始数据,但格式相同):
http://127.0.0.1:8888/XXXXXXXXX/httpXmlServlet
<?xml version=“1.0” encoding = “GB2312”?>
<COM>
<REQ name="commodity_query">
<USER_ID>0001</USER_ID>
<COMMODITY_ID>0000</COMMODITY_ID>
<SESSION_ID>4918081208706966071</SESSION_ID>
</REQ>
</COM>测试结果如下:
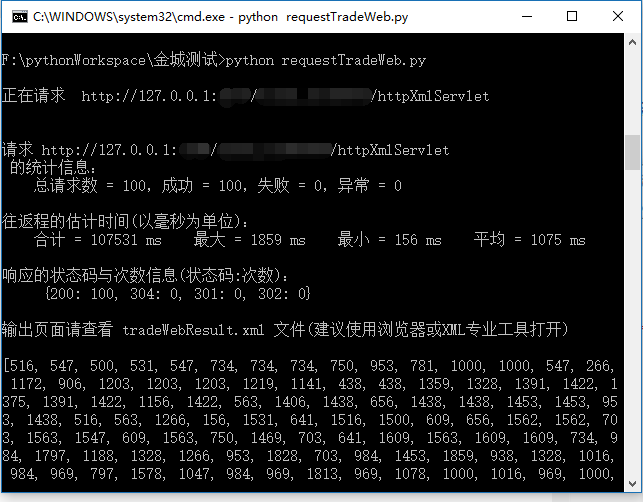
由于公司保密性要求,地址做了模糊处理,另外输出的tradeWebResult.xml结果页面也未展示。
以上仅为个人学习与使用Python过程的一个记录,难免会有程序设计或使用不当,如有更好的意见,欢迎指正。
注:此代码开发环境为Python 3.5 + windows,未在Python 2.x环境下测试
上一篇: python计算时间间隔
下一篇: Python2和Python的区别那个版
- openvpn linux客户端使用
52582
- H3C基本命令大全
52510
- openvpn windows客户端使用
42593
- H3C IRF原理及 配置
39504
- Python exit()函数
33919
- openvpn mac客户端使用
30885
- python全系列官方中文文档
29665
- python 获取网卡实时流量
24572
- 1.常用turtle功能函数
24416
- python 获取Linux和Windows硬件信息
22788
- LangGraph Studio可视化
97°
- LangSmith开发-应用入门
108°
- LangGraph开发-多轮对话问答机器人
184°
- LangGraph开发-条件分支/循环图实战
179°
- LangGraph开发-生态介绍,入门demo实战
209°
- LangChain-接入12306-HTTP MCP智能体
368°
- LangChain接入自定义爬虫-MCP工具
359°
- LangChain接入Filesystem-MCP工具
365°
- LangChain搭建MCP服务端和客户端流程
440°
- LangGraph与MCP技术概述
363°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
