pythonpcap原生python读取
发布时间:2019-09-23 17:06:55编辑:auto阅读(2640)
本文代码都由python编写,无需安装第三方拓展库,代码更新:https://github.com/mengdj/python
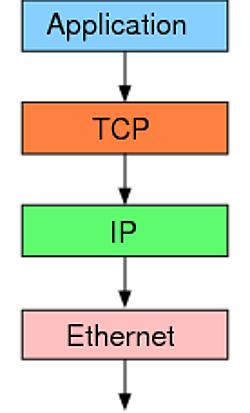
.pcap文件是一种简单网络包记录文件,较它的升级版.pcapng简单多了

可以看到.pcap文件,就由一个pcap文件头+无数个(pcap包头+包数据组成),我们只需要一个个解析即可,文件头用于描述.pcap文件本身(就一个文件头),包头则描述包的信息(抓取时间、长度等等),包的数据就是我们要的4层数据了(链路+网络+传输+应用),值得注意的是.pcap文件抓取的包是链路层抓取的,所以此时的包还没有经过重组,网络包重组(ip重组、tcp重组),本文暂不说明,后期可关注github,会用python实现的
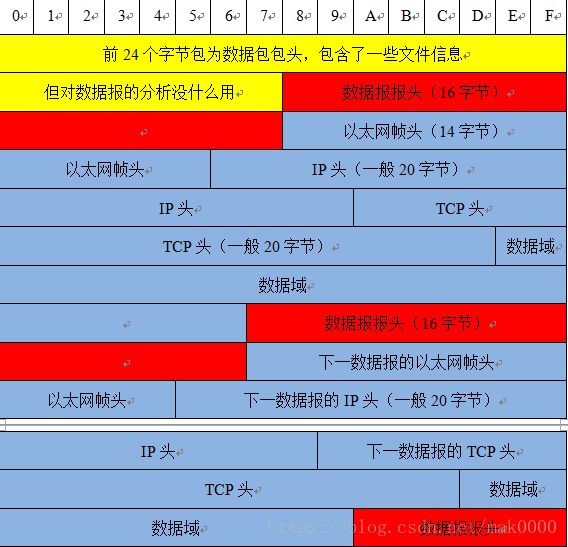
Pcap文件头24B各字段说明:
Magic: 4B:0×1A 2B 3C 4D:用来识别文件自己和字节顺序。0xa1b2c3d4用来表示按照原来的顺序读取,0xd4c3b2a1表示下面的字节都要交换顺序读取。一般,我们使用0xa1b2c3d4
Major: 2B,0×02 00:当前文件主要的版本号
Minor: 2B,0×04 00当前文件次要的版本号
ThisZone: 4B 时区。GMT和本地时间的相差,用秒来表示。如果本地的时区是GMT,那么这个值就设置为0.这个值一般也设置为0 SigFigs:4B时间戳的精度;全零
SnapLen: 4B最大的存储长度(该值设置所抓获的数据包的最大长度,如果所有数据包都要抓获,将该值设置为65535; 例如:想获取数据包的前64字节,可将该值设置为64)
LinkType: 4B链路类型
常用类型:
0 BSD loopback devices, except for later OpenBSD
1 Ethernet, and Linux loopback devices
6 802.5 Token Ring
7 ARCnet
8 SLIP
9 PPP
10 FDDI
100 LLC/SNAP-encapsulated ATM
101 “raw IP”, with no link
102 BSD/OS SLIP
103 BSD/OS PPP
104 Cisco HDLC
105 802.11
108 later OpenBSD loopback devices (with the AF_value in network byte order)
113 special Linux “cooked” capture
114 LocalTalk
现在我们分别用python来解析(注意解析时,每一层代码都只拆分出上层数据,然后交给上层自己处理,)
.pcap文件头处理 ==> .pcap包处理 ==> 链路层==> 网络层==> 传输层==> 应用层
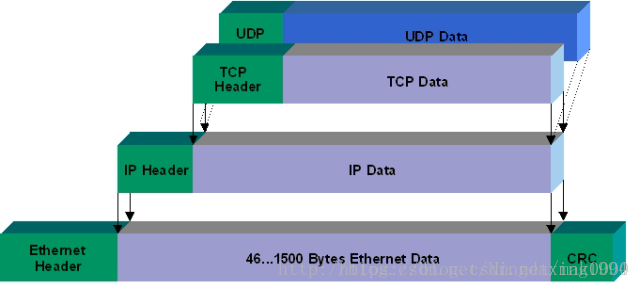
1.pcap.py 文件头处理
解析文件头以及众多包,拿到包数据但不细节,解析包的工作我们放到包处理来做,同时考虑到文件通常很大,我们用生成器来处理遍历操作
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
__author__ = "mengdj@outlook.com"
from pcap.proc.packet import Packet
from pcap.proc.util import BytesBuffer
from pcap.proc.util import BytesOrder
class PcapHead(object):
"""pcap文件头 24B"""
_magic_number = None
_version_major = None
_version_minor = None
_thiszone = None
_sigfigs = None
_snaplen = None
_link_type = None
def __init__(self, data):
assert len(data) == 24
self._magic_number = data[:4]
if PcapHead.signature(self._magic_number) is False:
raise Exception("不支持的文件格式")
self._version_major = BytesOrder.bytes2int(data[4:6])
self._version_minor = BytesOrder.bytes2int(data[6:8])
self._thiszone = BytesOrder.bytes2int(data[8:12])
self._sigfigs = BytesOrder.bytes2int(data[12:16])
self._snaplen = BytesOrder.bytes2int(data[16:20])
self._link_type = BytesOrder.bytes2int(data[20:24])
def __str__(self):
return "order:%s magor:%d minor:%d zone:%d sig:%d snap_len:%d type:%d" % (
BytesOrder.order, self._version_major, self._version_minor, self._thiszone, self._sigfigs, self._snaplen,
self._link_type)
@staticmethod
def signature(data):
"""验证签名同时确定排序,虽然还无法读取到大小端但不影响"""
sig = BytesOrder.bytes2int(data)
if sig == 0xa1b2c3d4:
BytesOrder.order = "big"
return True
elif sig == 0xd4c3b2a1:
BytesOrder.order = "little"
return True
return False
class Pcap(object):
""".pcap解析类"""
__head = None
__ret = 0
def parse(self, file, buffSize=2048):
"""
解析pcap文件,返回值为一个生成器 yield
:param file:缓冲文件大小
:param buffSize:
:return:返回一个生成器(用于处理大包)
"""
assert file != ""
_buff = BytesBuffer()
_packet = None
ret = 0
with open(file, "rb") as o:
ctx = None
while 1:
# 优先处理缓冲区数据(如果缓存数据超过了指定大小)
bsize = len(_buff)
if bsize > 0:
if bsize >= buffSize:
ctx = _buff.getvalue()
else:
_buff.write(o.read(buffSize))
ctx = _buff.getvalue()
_buff.clear()
else:
ctx = o.read(buffSize)
size = len(ctx)
if size > 0:
if self.__head is None:
# 文件头占24字节
if size >= 24:
self.__head = PcapHead(ctx[:24])
size -= 24
ctx = ctx[24:]
else:
_buff.write(ctx)
# 分析包头(包头占16字节)
if size > 16:
if _packet is None:
_packet = Packet()
ctx, size = _packet.parse(ctx)
if _packet.finish():
yield _packet
ret += 1
_packet = None
if size > 0:
_buff.write(ctx)
else:
ctx, size = _packet.parse(ctx)
if _packet.finish():
yield _packet
ret += 1
_packet = None
if size > 0:
_buff.write(ctx)
else:
_buff.write(ctx)
else:
break
del ctx
del _buff
self.__ret = ret
def __len__(self):
return self.__ret
@property
def head(self):
"""获取包头,务必保证有调用parse后才能获得包头"""
return self.__head
2.packet.py 数据包处理
处理详细包数据,并解析一层数据(交给链路层处理,获得链路层MAC实例)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
__author__ = "mengdj@outlook.com"
from pcap.proc.mac import MAC
from pcap.proc.util import BytesBuffer, BytesOrder, ProcData
class PacketHead(object):
"""包头 16B"""
_ts_sec = 0
_ts_usec = 0
_incl_len = 0
_orig_len = 0
def __init__(self, data):
self._ts_sec = BytesOrder.bytes2int(data[:4])
self._ts_usec = BytesOrder.bytes2int(data[4:8])
self._incl_len = BytesOrder.bytes2int(data[8:12])
self._orig_len = BytesOrder.bytes2int(data[12:16])
@property
def sec(self):
return self._ts_sec
@property
def usec(self):
return self._ts_usec
@property
def incl(self):
return self._incl_len
@property
def orig(self):
return self._orig_len
def __str__(self):
return "PACKET sec:%d usec:%d incl len:%d orig len:%d" % (
self._ts_sec, self._ts_usec, self._incl_len, self._incl_len)
class Packet(ProcData):
"""数据包(未拆包)"""
_head = None
_buff = None
name = "Packet"
def __init__(self):
super(ProcData, self).__init__()
self._buff = BytesBuffer()
def parse(self, data):
"""
解析包数据
:param data: 字节数据
:return: data,size
"""
size = len(data)
assert size > 0
if self._head is None:
self._head = PacketHead(data)
size -= 16
data = data[16:]
if size > 0:
_bs = len(self._buff)
if _bs + size < self._head.incl:
self._buff.write(data)
size = 0
data = None
else:
offset = self._head.incl - _bs
self._buff.write(data[:offset])
data = data[offset:]
size -= offset
assert len(data) == size
return data, size
def __del__(self):
self._buff.close()
@property
def head(self):
return self._head
@property
def data(self):
return MAC(self._buff.getvalue(),None)
def finish(self):
return len(self._buff) == self._head.incl
3.mac.py 链路层
链路层其实很简单,链路层由 14字节(存储目标mac,来源mac,上层协议类型)包头+数据构成 其实我们可以发现底层协议都会有一个字段,然后后面直接上层协议数据
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
__author__ = "mengdj@outlook.com"
from pcap.proc.arp import ARP
from pcap.proc.ip import IP
from pcap.proc.ipv6 import IPV6
from pcap.proc.util import ProcData
class MAC(ProcData):
"""mac协议 14B+"""
_dst = None
_src = None
_type = None
_data = None
def __init__(self, data, upper):
super(MAC, self).__init__(upper)
size = len(data)
assert size > 18
self._dst = data[:6]
self._src = data[6:12]
self._type = data[12:14]
# fcs校验字段 self._fcs = data[size - 4:]
self._data = data[14:]
def __str__(self):
return "MAC dst=>%s src=>%s type:%s" % (self.dst_desc, self.src_desc, self.type_desc)
@property
def dst_desc(self):
return [hex(s).replace("0x", "").upper() for s in self._dst]
@property
def src_desc(self):
return [hex(s).replace("0x", "").upper() for s in self._src]
@property
def type_desc(self):
return [hex(i) for i in self._type]
@property
def dst(self):
return self._dst
@property
def src(self):
return self._src
@property
def type(self):
return self._type
@property
def data(self):
ret = None
if self._type[0] == 0x08:
if self._type[1] == 0x00:
# ipv4 0x0800
ret = IP(self._data, self)
elif self._type[1] == 0x06:
# arp 0x0806
ret = ARP(self._data, self)
elif self._type[0] == 0x86:
if self._type[1] == 0xdd:
# ipv6 0x86dd
ret = IPV6(self._data, self)
return ret
4.ip.py 网络层(ip协议)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
__author__ = "mengdj@outlook.com"
from pcap.proc.tcp import TCP
from pcap.proc.udp import UDP
from pcap.proc.util import BytesOrder, ProcData
class Services(object):
"""IP服务类型"""
PRIORITY = 0
DELAY = 0
THROUGHPUT = 0
RELIABILITY = 0
COST = 0
RESERVED = 0
def __init__(self, ser):
pass
class Flag(object):
"""IP分片标志(python偏移真坑)"""
DF = 0
MF = 0
def __init__(self, flag):
"""
如果DF=0,那么标识不允许分段;DF=1则是表示这个数据包允许分段。MF=0表示分完段
之后这个数据段是整个包的最后那段,MF=1则是不是最后段的标志
"""
self.DF = ((~(~(1 << 6))) & flag) >> 6
self.MF = ((~(~(1 << 5))) & flag) >> 5
def __str__(self):
return "(DF:%d MF:%d)" % (self.DF, self.MF)
class IP(ProcData):
"""ip协议(ipv4) 20B"""
_header_version_len = 0
_service_set = 0
# 标示IP头部有多少个4字节,IP头部最长是60字节
_total_len = 0
_id = 0
_flag_offset = 0
_time_to_live = 0
_protocol = 0
_check_sum = 0
_src = 0
_dst = 0
_data = None
_flag = None
def __init__(self, data, upper):
super(IP, self).__init__(upper)
# 版本和长度各占4位,一共1个字节
self._header_version_len = data[0]
self._service_set = data[1]
self._total_len = data[2:4]
self._id = data[4:6]
self._flag_offset = data[6:8]
self._time_to_live = data[8]
self._protocol = data[9]
self._check_sum = data[10:12]
self._src = data[12:16]
self._dst = data[16:20]
self._data = data[self.head_len_byte:]
def __str__(self):
return (
"IPv%d src:%s dst:%s len(header):%d service:%s len(total):%d id:%d flag:%s "
"time to live:%d protocol:%d check sum:%s payload:%d" %
(
self.version, self.src, self.dst, self.head_len_byte, bin(self._service_set), self.total_len,
self.id,
self.flag, self.time_to_live, self._protocol,
self._check_sum, len(self._data))
)
@property
def version(self):
return self._header_version_len >> 4
@property
def head_len(self):
return (0xff >> 4) & self._header_version_len
@property
def flag(self):
if self._flag is None:
self._flag = Flag(self._flag_offset[0])
return self._flag
@property
def total_len(self):
return BytesOrder.bytes2int(self._total_len, "big")
@property
def time_to_live(self):
return self._time_to_live
@property
def id(self):
"""IP序号"""
return BytesOrder.bytes2int(self._id, "big")
@property
def src(self):
return [i for i in self._src]
@property
def dst(self):
return [i for i in self._dst]
@property
def head_len_byte(self):
"""头部字节数"""
return self.head_len << 2
@property
def data(self):
"""获取传输层协议"""
ret = None
# 46~1500 检测是否有填充数据(既数据部分不满足46字节会填充,传递时候要过滤掉这部分数据)
# tcp自身有分包机制,不用处理分包,其他协议需要处理分包
data = self._data[:self.total_len - 20]
if self._protocol == 0x06:
ret = TCP(data, self)
elif self._protocol == 0x11:
ret = UDP(data, self)
return ret
5.1.tcp.py 传输层(tcp协议)
tcp协议是一个很复杂的协议,如果你了解透了会对以后设计应用层协议大有帮助的,篇幅有限在这不废话,如稳定性的udp实现,其实就是tcp的另外一个实现
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
__author__ = "mengdj@outlook.com"
from pcap.proc.util import BytesOrder, ProcData
class Flag(object):
"""
CWR:拥塞窗口减少标志被发送主机设置,用来表明它接收到了设置ECE标志的TCP包。拥塞窗口是被TCP维护
的一个内部变量,用来管理发送窗口大小。
ECE:ECN响应标志被用来在TCP3次握手时表明一个TCP端是具备ECN功能的,并且表明接收到的TCP包的IP
头部的ECN被设置为11。更多信息请参考RFC793。
URG:紧急标志。紧急标志为"1"表明该位有效。
ACK:确认标志。表明确认编号栏有效。大多数情况下该标志位是置位的。TCP报头内的确认编号栏内包含的
确认编号(w+1)为下一个预期的序列编号,同时提示远端系统已经成功接收所有数据。
PSH:推标志。该标志置位时,接收端不将该数据进行队列处理,而是尽可能快地将数据转由应用处理。在处理
Telnet或rlogin等交互模式的连接时,该标志总是置位的。
RST:复位标志。用于复位相应的TCP连接。
SYN:同步标志。表明同步序列编号栏有效。该标志仅在三次握手建立TCP连接时有效。它提示TCP连接的服务端
检查序列编号,该序列编号为TCP连接初始端(一般是客户端)的初始序列编号。在这里,可以把TCP序列
编号看作是一个范围从0到4,294,967,295的32位计数器。通过TCP连接交换的数据中每一个字节都经
过序列编号。在TCP报头中的序列编号栏包括了TCP分段中第一个字节的序列编号。
FIN:结束标志。
"""
CWR = 0
ECE = 0
URG = 0
ACK = 0
PSH = 0
RST = 0
SYN = 0
FIN = 0
def __init__(self, flag):
# 取反补位(一次1字节的后6位)
self.CWR = ((~(~(1 << 7))) & flag) >> 7
self.ECE = ((~(~(1 << 6))) & flag) >> 6
self.URG = ((~(~(1 << 5))) & flag) >> 5
self.ACK = ((~(~(1 << 4))) & flag) >> 4
self.PSH = ((~(~(1 << 3))) & flag) >> 3
self.RST = ((~(~(1 << 2))) & flag) >> 2
self.SYN = ((~(~(1 << 1))) & flag) >> 1
self.FIN = ((~(~1)) & flag)
def __str__(self):
return "(CWR:%d ECE:%d URG:%d ACK:%d PSH:%d RST:%d SYN:%d FIN:%d)" % (
self.CWR, self.ECE, self.URG, self.ACK, self.PSH, self.RST, self.SYN, self.FIN)
class TCP(ProcData):
"""UDP协议 20B+,暂未处理分段数据 """
_src = 0
_dst = 0
# 发送、确认编号
_seq_no = 0
_ack_no = 0
_header_len_reserved = 0
_reserved_flag = 0
_wnd_size = 0
_check_sum = 0
# 紧急指针(偏移量)
_urqt_p = 0
_option = []
_flag = None
_data = []
def __init__(self, data, upper):
super(TCP, self).__init__(upper)
self._src = data[:2]
self._dst = data[2:4]
self._seq_no = data[4:8]
self._ack_no = data[8:12]
# 4+4
self._header_len_reserved = data[12]
# 2+6
self._reserved_flag = data[13]
self._wnd_size = data[14:16]
self._check_sum = data[16:18]
self._urqt_p = data[18:20]
# 其他可选字段
if self.header_len > 20:
self._option = data[20:self.header_len]
self._data = data[self.header_len:]
def __str__(self):
return "TCP src(port):%d dst(port):%d seq:%d ack:%d len(header):%d " \
"flag:%s win:%d check_sum:%s urqt_p:%d option:%d payload:%d" % (
self.src, self.dst, self.seq, self.ack, self.header_len, self.flag, self.wnd_size,
self.check_sum, self.urqt_p,
len(self._option),
len(self._data))
def __len__(self):
return len(self._data)
@property
def src(self):
return BytesOrder.bytes2int(self._src, "big")
@property
def option(self):
"""分析tcp的可选项字段(分析了常用字段)"""
size = len(self._option)
ret = []
if size > 0:
option = self._option
while size > 0:
if option[0] == 0x00:
ret.append({"END": option[0]})
break
if option[0] == 0x01:
ret.append({"NOP": option[0]})
size -= 1
option = option[1:]
elif option[0] == 0x02:
# MSS
ret.append({"MSS": {"length": option[1], "value": BytesOrder.bytes2int(option[2:4], "big")}})
size -= 4
option = option[4:]
elif option[0] == 0x03:
# 窗口扩大因子
ret.append({"WSALE": {"length": option[1], "shift_count": option[2]}})
size -= 3
option = option[3:]
elif option[0] == 0x04:
# SACK
ret.append({"SACK": {"length": option[1]}})
size -= 2
option = option[2:]
elif option[0] == 0x08:
# 时间戳
ret.append({"TIMESTAMP": {"length": option[1], "value": BytesOrder.bytes2int(option[2:6], "big"),
"repl_value": BytesOrder.bytes2int(option[6:10], "big")}})
size -= 10
option = option[10:]
else:
break
else:
ret = None
return ret
@property
def flag(self):
"""获取标志对象"""
if self._flag is None:
self._flag = Flag(self._reserved_flag)
return self._flag
@property
def flag_desc(self):
return bin(self._reserved_flag)
@property
def dst(self):
return BytesOrder.bytes2int(self._dst, "big")
@property
def seq(self):
"""获取序列号"""
return BytesOrder.bytes2int(self._seq_no, "big")
@property
def ack(self):
"""获取确认号"""
return BytesOrder.bytes2int(self._ack_no, "big")
@property
def header_len(self):
"""获取头部长度"""
return (self._header_len_reserved >> 4) << 2
@property
def wnd_size(self):
"""获取滑动窗口大小"""
return BytesOrder.bytes2int(self._wnd_size, "big")
@property
def check_sum(self):
"""获取校验"""
return self._check_sum
@property
def urqt_p(self):
"""获取紧急指针"""
return BytesOrder.bytes2int(self._urqt_p, "big")
@property
def data(self):
"""获取原始包(可能包含分段数据,此数据未进行重组)"""
return self._data
5.1.udp.py 传输层(udp协议)
udp协议头(首部)占用8字节,记录端口号,头长度以及校验和(非必须)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
__author__ = "mengdj@outlook.com"
from pcap.proc.util import BytesOrder, ProcData
class UDP(ProcData):
"""UDP 8B"""
_src = 0
_dst = 0
# UDP头部和UDP数据的总长度字节
_header_len = 0
_check_sum = 0
_data = None
def __init__(self, data, upper):
super(UDP, self).__init__(upper)
self._src = data[:2]
self._dst = data[2:4]
self._header_len = data[4:6]
self._check_sum = data[6:8]
self._data = data[8:]
def __str__(self):
return "UDP src port:%d dst:%d header_len:%d check_sum:%s" % (
self.src, self.dst, self.header_len, self.check_sum)
@property
def src(self):
return BytesOrder.bytes2int(self._src, "big")
@property
def dst(self):
return BytesOrder.bytes2int(self._dst, "big")
@property
def header_len(self):
return BytesOrder.bytes2int(self._header_len, "big")
@property
def check_sum(self):
return self._check_sum
@property
def data(self):
return self._data
6.基础类(封装了字节大小端转换、字节缓冲区操作)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
__author__ = "mengdj@outlook.com"
from io import BytesIO
class ProcData(object):
__upper = 0
def __init__(self, upper=None):
self.__upper = upper
@property
def data(self):
"""返回上层数据,未处理分片"""
pass
@property
def upper(self):
return self.__upper
class AppProcData(object):
"""此接口由应用层来实现"""
def __init__(self):
pass
def find(self, data):
"""校验数据并完成初始化,成功返回self,链式调用"""
pass
class BytesOrder(object):
"""大小端排序工具类"""
order = "big"
@staticmethod
def bytes2int(data, ord=""):
if ord == "":
ord = BytesOrder.order
return int.from_bytes(data, ord)
class BytesBuffer(BytesIO):
"""封装BytesIO,增加重置"""
# 写入长度缓存
__length = 0
# 统计写入次数
__count = 0
def __len__(self):
"""获取长度,使用切片而不复制数据,同时增加计算缓存"""
if self.__length == 0:
self.__length = len(self.getbuffer())
return self.__length
def clear(self):
"""清理缓存区然后重置索引,seek必须调用"""
self.truncate(0)
self.seek(0)
self.__length = 0
self.__count = 0
def write(self, *args, **kwargs):
self.__length = 0
self.__count += 1
return super(BytesBuffer, self).write(*args, **kwargs)
def writelines(self, *args, **kwargs):
self.__length = 0
self.__count += 1
return super(BytesBuffer, self).writelines(*args, **kwargs)
def count(self):
return self.__count
值得注意的是,由于抓取的链路层的数据,尚未进行重组MTU,MSS,因此抓到是可能是分段数据而不是完整的数据,分段操作,对于tcp(mss)由自己完成,其他则右IP协议完成,所以你发一个tcp包大小为1537字节,最终可能拆分成2个包,每个包都会带上tcp协议头,tcp的mss通常为1460字节;而ip分段则只会第一个包带上首部,分包重组需要详细了解协议知识,关于tcp和ip分包重组,请关注本博
【阿里云】12.12来了!购买云产品即享低至2折,2018最后一波了 https://m.aliyun.com/act/team1212?params=N.4qR9SajEMx

上一篇: [Python]数据结构--Bitmap
下一篇: python | gtts 将文字转化为
- H3C基本命令大全
52700
- H3C IRF原理及 配置
39700
- Python exit()函数
34076
- python全系列官方中文文档
29827
- python 获取网卡实时流量
24727
- 1.常用turtle功能函数
24561
- python 获取Linux和Windows硬件信息
22938
- 天天基金网数据接口
16315
- Selenium使用代理IP&无头模式访问网站
14600
- Selenium&Pytesseract模拟登录+验证码识别
14107
- LangGraph Studio可视化
310°
- LangSmith开发-应用入门
313°
- LangGraph开发-多轮对话问答机器人
385°
- LangGraph开发-条件分支/循环图实战
380°
- LangGraph开发-生态介绍,入门demo实战
422°
- LangChain-接入12306-HTTP MCP智能体
554°
- LangChain接入自定义爬虫-MCP工具
529°
- LangChain接入Filesystem-MCP工具
556°
- LangChain搭建MCP服务端和客户端流程
635°
- LangGraph与MCP技术概述
560°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
