python爬虫——爬取古诗名句
发布时间:2019-08-31 09:47:05编辑:auto阅读(2046)
一. 概要
1.通过python爬虫循环爬取古诗词网站古诗名句
2.落地到本地数据库
二. 页面分析
首先通过firedebug进行页面定位: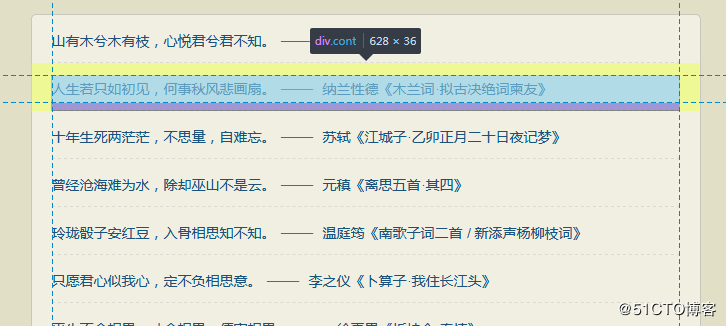
其次源码定位: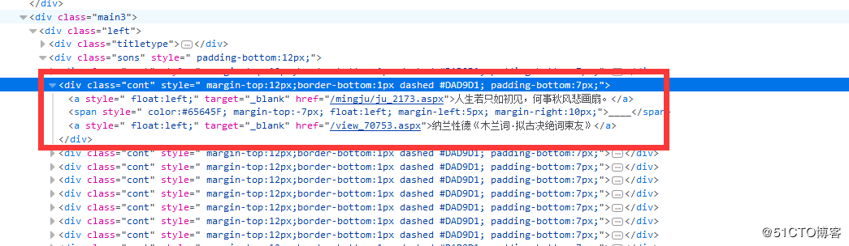
最终生成lxml etree定位div标签源码:
response = etree.HTML(data)
for row in response.xpath('//div[@class="left"]/div[@class="sons"]/div[@class="cont"]'):
content = row.xpath('a/text()')[0]
origin = row.xpath('a/text()')[-1]
self.db.add_new_row('mingJuSpider', {'content': content, 'origin': origin, 'createTime': str(date.today())})三. 执行结果
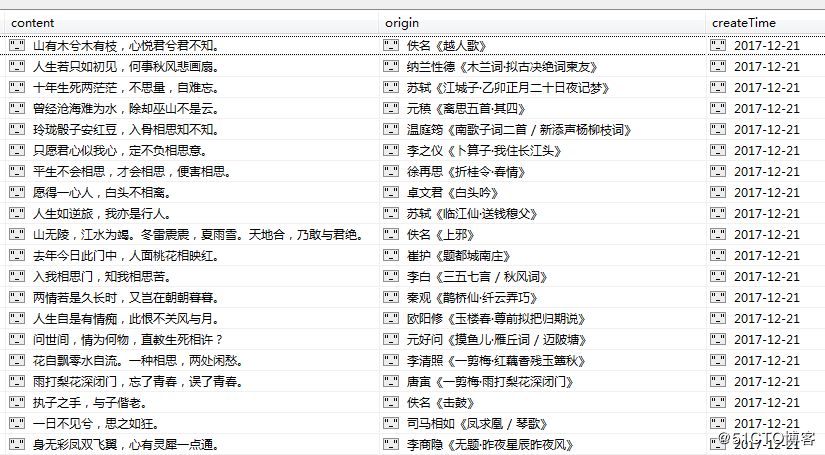
四. 脚本源码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''
@Date : 2017/12/21 12:35
@Author : kaiqing.huang
@File : mingJuSpider.py
'''
from utils import MySpider, MongoBase
from datetime import date
from lxml import etree
import sys
class mingJuSpider():
def __init__(self):
self.db = MongoBase()
self.spider = MySpider()
def download(self):
for pageId in range(1,117):
url = 'http://so.gushiwen.org/mingju/Default.aspx?p={}&c=&t='.format(pageId)
print url
data = self.spider.get(url)
if data:
self.parse(data)
def parse(self, data):
response = etree.HTML(data)
for row in response.xpath('//div[@class="left"]/div[@class="sons"]/div[@class="cont"]'):
content = row.xpath('a/text()')[0]
origin = row.xpath('a/text()')[-1]
self.db.add_new_row('mingJuSpider', {'content': content, 'origin': origin, 'createTime': str(date.today())})
if __name__ == '__main__':
sys.setrecursionlimit(100000)
do = mingJuSpider()
do.download()
上一篇: Python设计模式——单例模式
下一篇: Python进行自动化测试工具
- openvpn linux客户端使用
52456
- H3C基本命令大全
52380
- openvpn windows客户端使用
42477
- H3C IRF原理及 配置
39390
- Python exit()函数
33836
- openvpn mac客户端使用
30791
- python全系列官方中文文档
29549
- python 获取网卡实时流量
24466
- 1.常用turtle功能函数
24318
- python 获取Linux和Windows硬件信息
22699
- LangChain-接入12306-HTTP MCP智能体
227°
- LangChain接入自定义爬虫-MCP工具
231°
- LangChain接入Filesystem-MCP工具
241°
- LangChain搭建MCP服务端和客户端流程
296°
- LangGraph与MCP技术概述
239°
- LangChain 1.0-Agent中间件-实现闭环(批准-编辑-拒绝动作)
372°
- LangChain 1.0-Agent中间件-汇总消息
373°
- LangChain 1.0-Agent中间件-删除消息
391°
- LangChain 1.0-Agent中间件-消息压缩
392°
- LangChain 1.0-Agent中间件-多模型动态选择
431°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
